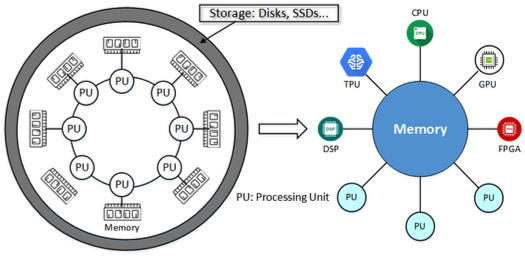
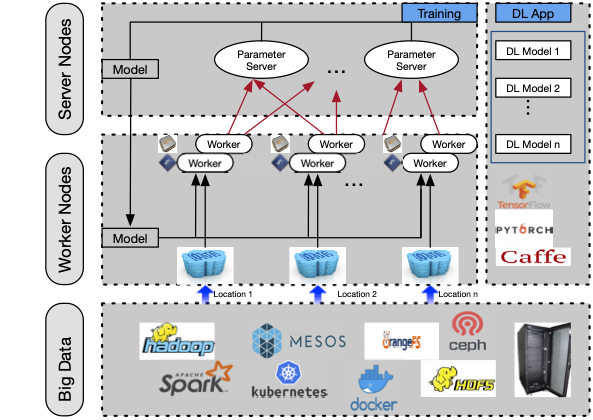
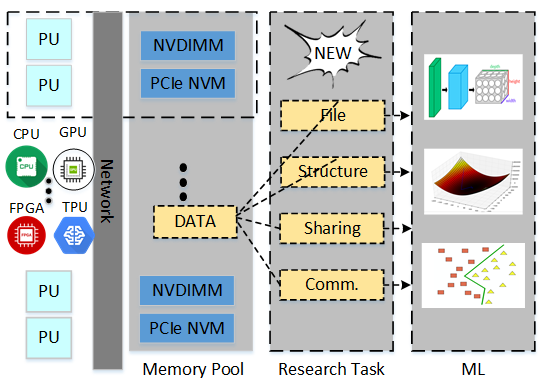
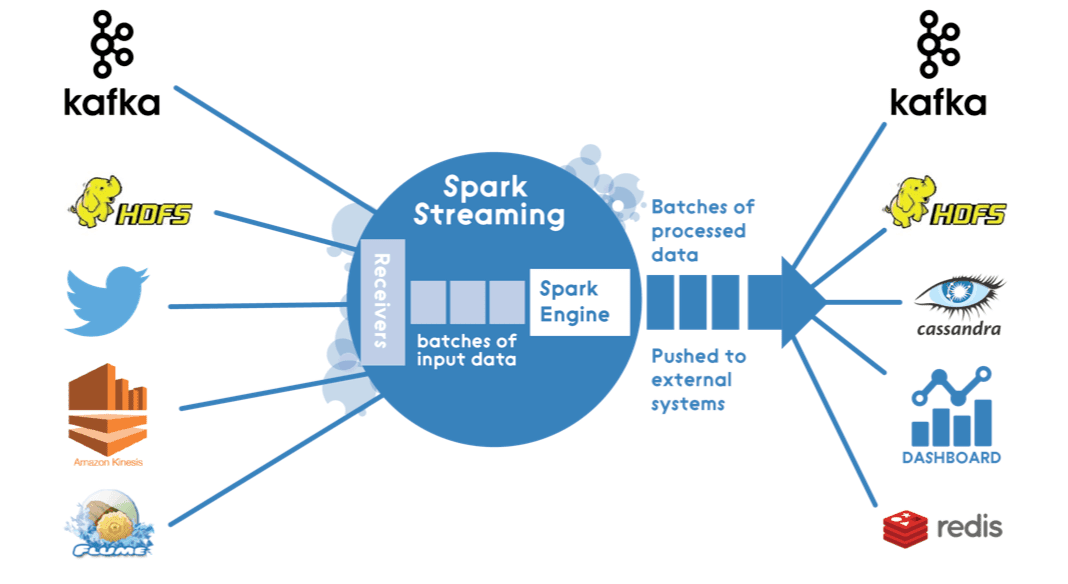
As AI is getting increasingly popular today, Machine Learning (ML) is becoming essential for a lot of
research areas, including computer vision, speech recognition, and natural language processing.
Typically, deploying ML models at scale involves virtualization, networking, and infrastructure-related
knowledge. The scale and complexity of ML workflows makes it hard to provision and manage
resources – a burden for ML practitioners that hinders both their productivity and effectiveness.
On the other hand, cloud computing has changed the way we model software and solutions.
There are various first-generation serverful cloud services (e.g., IaaS, PaaS and SaaS) to provide
efficient, economic and intelligent solutions for ML models. Recently, following the footsteps of
traditional cloud computing, the next-generation cloud – “serverless” architectures,
represented by AWS Lambda and Google Cloud Functions, have emerged as a burgeoning computation model
to further reduce costs and improve manageability in cloud computing.